上次的內容中,我們討論到在Pytorch中訓練一個AI模型的完整流程,並介紹了要如何準備訓練模型所需要的資料集,今天我們將接著往下講如何建立與訓練一個模型,並且在訓練好之後評估模型的表現。
和資料集一樣,建立模型的方式可以從Pytorch中提供的架構直接拿來用,或是由我們自己定義都可以,以下將分別介紹這兩種方式。

import torchvision.models as models
# vgg16 = models.vgg16() #僅有模型架構,沒有預訓練權重
vgg16 = models.vgg16(pretrained=True) #模型架構與預訓練權重
print(vgg16) #直接用print便可查看模型架構
import torch
import torch.nn as nn
import torchvision
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# Hyperparameters
input_size = 28 * 28 # MNIST images are 28x28 pixels
hidden_size = 128 # Number of neurons in the hidden layer
num_classes = 10 # Number of output classes (0-9 digits)
# Initialize the model
model = MLP(input_size, hidden_size, num_classes)
print(model)
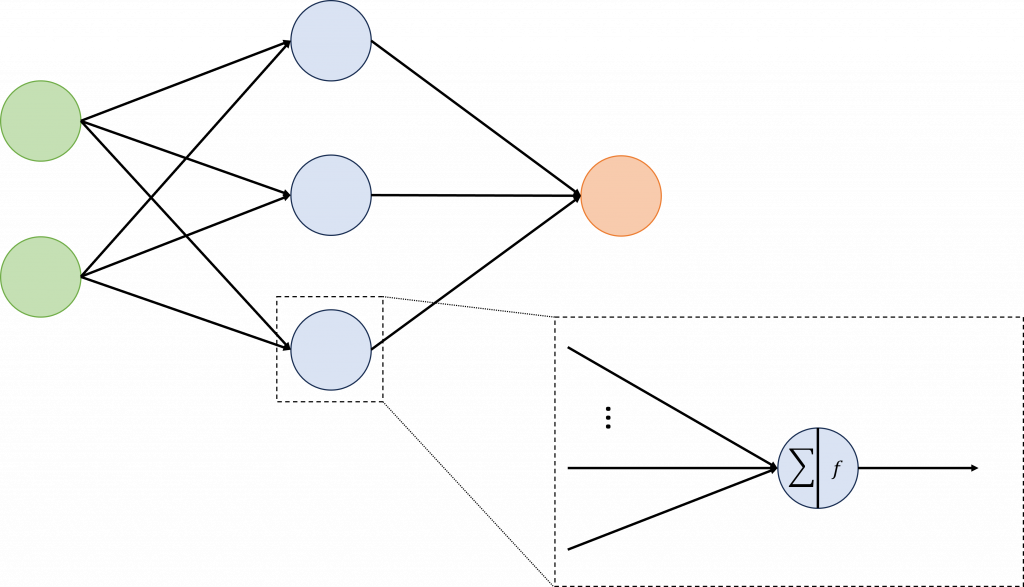
def forward(self, x):的部分,正向傳播需要明確寫出模型中的每一層訊號要如何傳遞到下一層,這樣才能讓Pytorch建立計算圖,替我們處理反向傳播的運算。import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# Define the MLP model
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# Hyperparameters
input_size = 28 * 28 # MNIST images are 28x28 pixels
hidden_size = 128 # Number of neurons in the hidden layer
num_classes = 10 # Number of output classes (0-9 digits)
learning_rate = 0.001
batch_size = 64
num_epochs = 10
# Load MNIST dataset and apply transformations
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize((32,32)),transforms.Normalize((0.5,), (0.5,))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# Initialize the model
model = MLP(input_size, hidden_size, num_classes)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
total_step = len(train_loader)
for epoch in range(num_epochs): # 總共需要跑完幾次全部的訓練資料
############## 跑完所有訓練資料一次 ###############
for i, (images, labels) in enumerate(train_loader):
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss.backward()這個指令,使用Pytorch中的動態計算圖計算出loss對所有權重的梯度,最後,使用optimizer.step()這個指令,利用梯度下降法來更新所有參數。optimizer.zero_grad()
loss.backward()
optimizer.step()

